
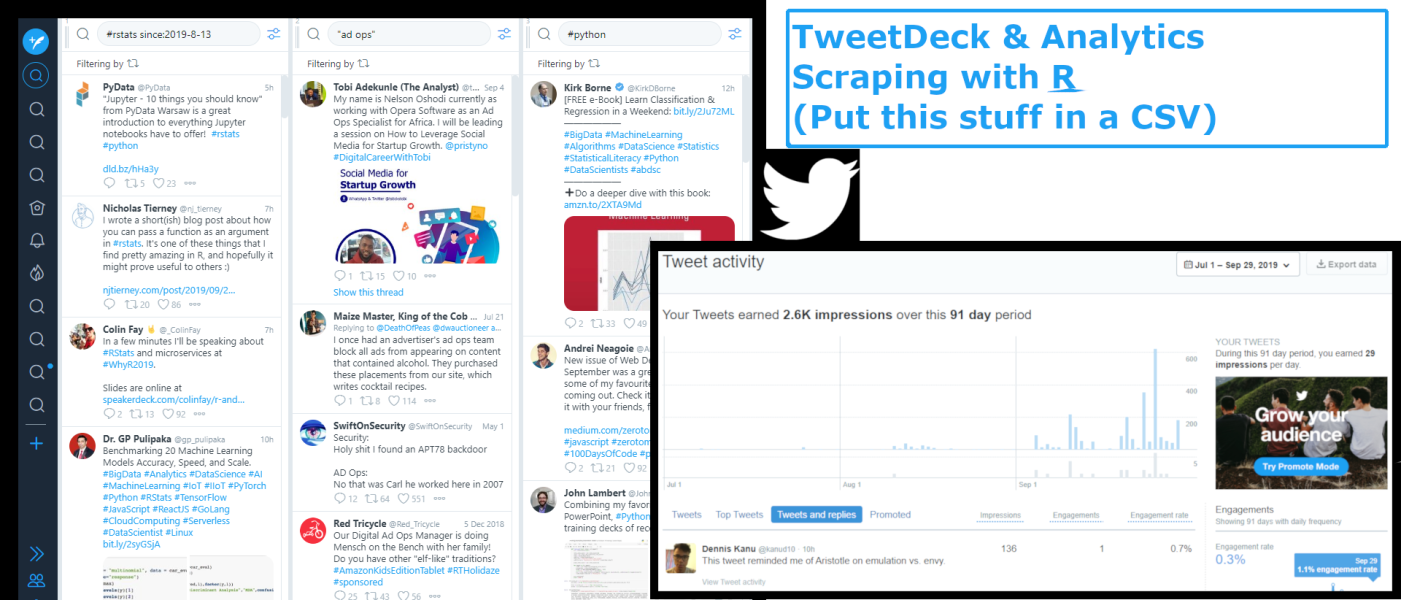
Twitter offers tools to analyze tweet performance of your own accounts via twitter analytics and the accounts of others via tweetdeck. Unfortunately, the platforms have limited data export functionality; there is not a clean easy way to export data from the web user interface.
The method outlined in this post avoids Twitter API fees and is compliant with TOS if you download html files locally. You can download local html copies of the webpages found at analytics.twitter.com and tweetdeck.twitter.com that are associated with your account. The full code can be found on GitHub.
There are 4 other files that you’ll want to include in the same directory where you downloaded the html files:
- twitter_scraping_css.json
- twitter-analytics-main.r
- twitter-tweetdeck-main.r
- Helpers.R
twitter_scraping_css.json
This json file contains css selectors templates for targeting relevant structured data in twitter analytics and tweetdeck html files. The css selectors for tweetdeck are written generically with a %s parameter in the nth-child selector.
{
"tweetdeck": {
"date.selector": "#container > div > section:nth-child(%s) time > a",
"link.selector": "#container > div > section:nth-child(%s) time > a",
"author.selector": "#container > div > section:nth-child(%s) div[class='nbfc '] > span > span",
"replies.selector": "#container > div > section:nth-child(%s) span.pull-right.icon-reply-toggle.margin-l--2.margin-t--1.txt-size--12.js-reply-count.reply-count",
"retweets.selector": "#container > div > section:nth-child(%s) span.pull-right.icon-retweet-toggle.margin-l--3.margin-t--1.txt-size--12.js-retweet-count.retweet-count",
"favorites.selector": "#container > div > section:nth-child(%s) span.pull-right.icon-favorite-toggle.margin-l--2.margin-t--1.txt-size--12.js-like-count.like-count"
},
"twitter.analytics": {
"imp.selector": "#tweet-activity-container > ul div.tweet-activity-data.impressions.text-right.col-md-1",
"eng.selector": "#tweet-activity-container > ul div.tweet-activity-data.metric.text-right.col-md-2",
"url.selector": "#tweet-activity-container > ul span.tweet-created-at > a"
}
}
Helpers.R
In the Helpers.R file the function TweetDeckColumnSelector modifies the generic css selectors so that a specific tweetdeck column is targeted.
#' Modify Generic CSS to Target Specific TweetDeck Column
#'
#' @param css string; specifying json file containing generic twitter css
#' @param column integer; tweetdeck column to be scraped
#'
#' @return list; strings with column specific css selectors
#' @export
#'
#' @examples
TweetDeckColumnSelector <- function(css, column){
td_column <- toString(column)
date.selector <- sprintf(css$tweetdeck$date.selector, column)
link.selector <- sprintf(css$tweetdeck$link.selector, column)
author.selector <- sprintf(css$tweetdeck$author.selector, column)
replies.selector <- sprintf(css$tweetdeck$replies.selector, column)
retweets.selector <- sprintf(css$tweetdeck$retweets.selector, column)
favorites.selector <- sprintf(css$tweetdeck$favorites.selector, column)
out <- list(column,
date.selector,
link.selector,
author.selector,
replies.selector,
retweets.selector,
favorites.selector
)
names(out) <- c('column',
'date.selector',
'link.selector',
'author.selector',
'replies.selector',
'retweets.selector',
'favorites.selector'
)
return(out)
}The function TweetDeckScrape takes a parsed tweetdeck html file and column specific css (the output of TweetDeckColumnSelector) as input arguments. It outputs a dataframe where each row contains information about date, author, number of replies, number of retweets, and number of favorites of each tweet in the tweetdeck column you targeted.
#' Scrape TweetDeck HTML File
#'
#' @param x string; specifying tweetdeck html file - recomend storing file locally
#' @param fmt_css list; containing strings of column specific css
#'
#' @return dataframe; date, tweet, author, replies, retweets, favorites
#' @export
#'
#' @examples
TweetDeckScrape <- function(x, fmt_css){
date <- x %>% html_nodes(fmt_css$date.selector) %>% html_text
tweet <- x %>% html_nodes(fmt_css$link.selector) %>% html_attr('href')
author <- x %>% html_nodes(fmt_css$author.selector) %>% html_text
replies <- x %>% html_nodes(fmt_css$replies.selector) %>% html_text
replies <- as.numeric(replies)
replies[is.na(replies)] <- 0
retweets <- x %>% html_nodes(fmt_css$retweets.selector) %>% html_text
retweets <- as.numeric(retweets)
retweets[is.na(retweets)] <- 0
favorites <- x %>% html_nodes(fmt_css$favorites.selector) %>% html_text
favorites <- as.numeric(favorites)
favorites[is.na(favorites)] <- 0
out <- as.data.frame(
cbind(date,
tweet,
author,
replies,
retweets,
favorites
)
)
colnames(out) <- c('date',
'tweet',
'author',
'replies',
'retweets',
'favorites')
return(out)
}The function TwitterAnalyticsScrape acts very similar to TweetDeckScrape. The key differences are that it takes a parsed twitter analytics html file and the css in twitter_scraping_css.json does not require any modification.
#' Scrape Twitter Analytics HTML File
#'
#' @param x string; specifying twitter analytics html file - recomend storing file locally
#' @param css string; specifying json file containing generic twitter css
#'
#' @return dataframe; url, impressions, engagements, engagement_rate
#' @export
#'
#' @examples
TwitterAnalyticsScrape <- function(x, css){
urls <- x %>% html_nodes(css$twitter.analytics$url.selector) %>%html_attr('href')
impressions <- x %>% html_nodes(css$twitter.analytics$imp.selector) %>%html_text %>% gsub(",","",.)
impressions <- as.numeric(impressions)
engagements <- x %>% html_nodes(css$twitter.analytics$eng.selector) %>%html_text %>% gsub(",","",.)
engagements <- engagements[c(TRUE, FALSE)]
engagements <- as.numeric(engagements)
engagment_rate <- engagements/impressions
out <- data.frame(
cbind(urls,
impressions,
engagements,
engagment_rate
)
)
colnames(out) <- c('url',
'impressions',
'engagements',
'engagement_rate')
return(out)
}twitter-tweetdeck-main.r
The file twitter-tweetdeck-main.r imports dependency packages and references the Helpers.R file. commandArgs is included so that the code may be run from the command line. The first argument passed is the tweetdeck column to target. All arguments after are references to the tweetdeck html files. Output is exported to a csv file.
##############################
## Tweetdeck - Main.R
##############################
##############################
## Imports
##############################
imports <- c('rvest','xml2','jsonlite','stringr','data.table','rio')
invisible(lapply(imports, require, character.only = TRUE))
source("Helpers.R", chdir = TRUE)
##############################
## Arg Parser
##############################
args <- commandArgs(trailingOnly = TRUE)
column <- as.integer(args[1])
args_list <- as.list(args[-1])
##############################
## Tweetdeck Scrape
##############################
##############################
## Read in stored HTML Files
## Read in CSS JSON
###############################
twitter_local <- lapply(args_list, read_html)
css <- read_json('twitter_scraping_css.json')
###############################
## Export
###############################
date_time <- toString(format(Sys.time(), "%Y-%m-%d %H-%M-%S"))
date_time <- toString(sprintf('%s - tweetdeck-out.csv',
date_time))
css_specific <- TweetDeckColumnSelector(css, column = column)
scrape <- lapply(twitter_local, TweetDeckScrape, css_specific)
scrape <- rbindlist(scrape)
export(scrape, date_time)twitter-analytics-main.r
The file twitter-analytics-main.r imports dependency packages and references the Helpers.R file. commandArgs is included so that the code may be run from the command line. Here all command line arguments are strings referencing the location of twitter analytics html files. Output is exported to a csv file.
##############################
## Twitter Analytics - Main.R
##############################
##############################
## Imports
##############################
imports <- c('rvest','xml2','jsonlite','stringr','data.table','rio')
invisible(lapply(imports, require, character.only = TRUE))
source("Helpers.R", chdir = TRUE)
##############################
## Command Line Args
##############################
args <- commandArgs(trailingOnly = TRUE)
args_list <- as.list(args)
##############################
## Twitter Analytics Scrape
##############################
##############################
## Read in HTML Files
## Read in CSS JSON
##############################
twitter_local <- lapply(args_list, read_html)
css <- read_json('twitter_scraping_css.json')
##############################
## Export
##############################
date_time <- toString(format(Sys.time(), "%Y-%m-%d %H-%M-%S"))
date_time <- toString(sprintf('%s - twitter-analytics-out.csv',
date_time))
scrape <- lapply(twitter_local, TwitterAnalyticsScrape, css)
scrape <- rbindlist(scrape)
export(scrape, date_time)In Action
- Download html file(s) from analytics.twitter.com
- Download html file from twitter.tweetdeck.com – observe that you can define fairly robust queries in a tweetdeck column
- Run code from tutorial
- Output is saved to csv
Tweetdeck – suppose that you saved your tweetdeck html file as tweetdeck-sample.html and that you’re interested in targeting data corresponding to the query in the first column:
cd C:\...\clever-bird-master C:\...\clever-bird-master>Rscript twitter-tweetdeck-main.r 1 tweetdeck-sample.html
Twitter Analytics – suppose that you saved your twitter analytics html file as twitter-analytics-sample.html:
cd C:\...\clever-bird-master C:\...\clever-bird-master>RScript twitter-analytics-main.r twitter-analytics-sample.html
With the csv output data you can analyze performance of any twitter account that you have credentials to and publicly available tweet performance for any tweetdeck query of your choice.